【n8n教程】:Compare Datasets节点,数据对比、轻松同步
在日常数据处理中,我们经常需要对比两个数据集的差异——比如同步MySQL和企业微信的客户数据、对比新旧库存数据、或者查找重复的客户记录。n8n的Compare Datasets节点正是为此而生,它能帮你快速找出两个数据源中的相同项、不同项、以及各自独有的数据。本教程将带你从零开始,掌握这个强大的数据对比工具。
一、Compare Datasets节点的核心功能
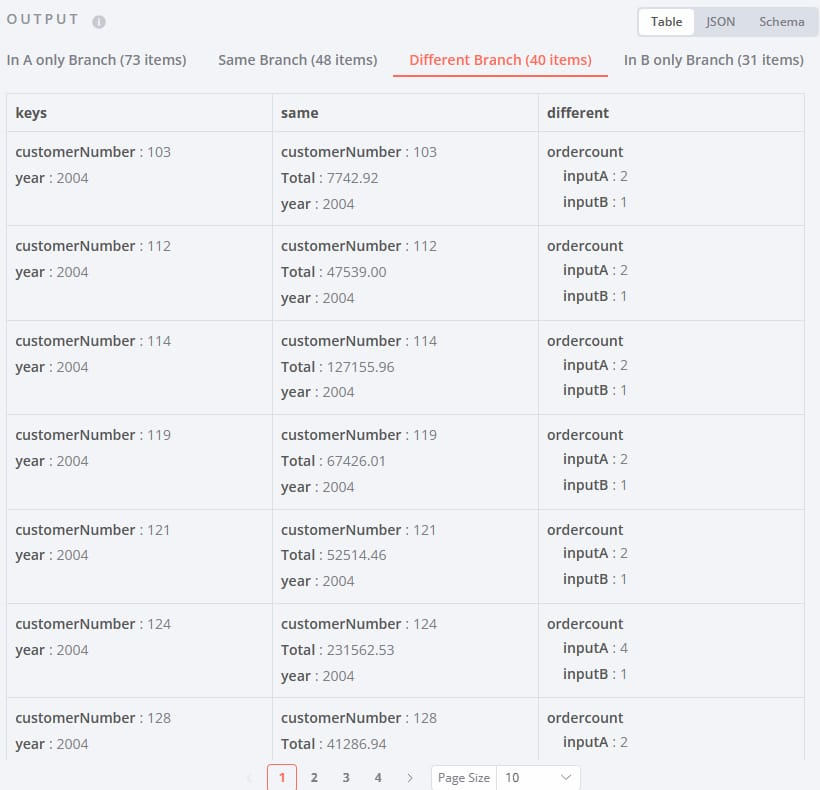
Compare Datasets节点的强大之处在于它能自动将两个数据集分成四个清晰的输出分支:
- 1. In A only Branch(仅在A中):只存在于第一个输入中的数据
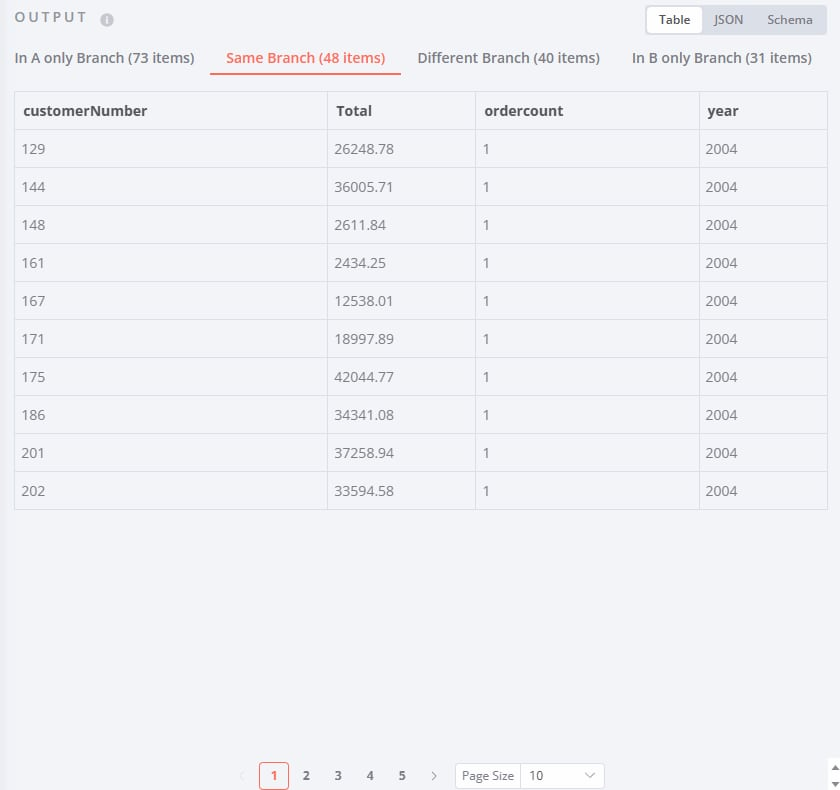
- 2. Same Branch(相同分支):两个输入中完全相同的数据
- 3. Different Branch(不同分支):匹配键相同但其他字段不同的数据
- 4. In B only Branch(仅在B中):只存在于第二个输入中的数据
这种清晰的分类让后续的数据处理变得非常简单——你可以轻松地针对不同类型的数据采取不同的操作。
二、节点参数详解
2.1 指定对比字段(必选)
这是最关键的配置,你需要告诉节点用哪个字段来匹配两个数据集:
- • Input A Field:输入流A中用于对比的字段名(例如:
email、customerNumber) - • Input B Field:输入流B中用于对比的字段名(通常与Input A Field相同)
小贴士:你可以通过点击Add Fields to Match添加多个对比字段,实现复合键匹配。比如同时用年份和客户编号来匹配数据。
2.2 差异处理策略
当节点发现数据有差异时,你需要决定保留哪个版本的数据:
| 选项 | 说明 | 适用场景 |
|---|---|---|
| Use Input A Version | 以输入A为准 | 单向数据同步,A是主数据源 |
| Use Input B Version | 以输入B为准 | 单向数据同步,B是主数据源 |
| Use a Mix of Versions | 混合使用两个版本 | 需要精细控制哪些字段用A,哪些用B |
| Include Both Versions | 同时保留A和B的版本 | 需要人工审核或对比的场景 |
Use a Mix of Versions详解:
- • Prefer:选择主要数据源(A或B)
- • For Everything Except:指定例外字段,这些字段将从另一个数据源获取(用逗号分隔多个字段)
2.3 模糊比较(Fuzzy Compare)
开启后,节点会容忍类型差异,让对比更宽松:
- • 数字
3和字符串"3"被视为相同 - • 不同格式的日期(如
2023-01-01和2023/01/01)也会被识别为匹配
建议:如果你的数据来源不同,格式可能不统一,建议开启此选项。
三、节点选项(Options)
点击节点的Options可以进行更精细的配置:
3.1 Fields to Skip Comparing(跳过对比的字段)
有些字段你不关心它是否相同(比如更新时间戳),可以在这里输入字段名来忽略它们。
示例:如果你只关心person.language是否相同,不在乎person.name,就把person.name添加到这里。这样即使名字不同,只要语言相同,节点也会认为数据匹配。
3.2 Disable Dot Notation(禁用点符号)
默认情况下,你可以用parent.child的方式引用嵌套字段。如果你的字段名本身就包含点号,需要开启此选项。
3.3 Multiple Matches(多重匹配处理)
当一个数据在另一个数据集中有多个匹配项时:
- • Include All Matches(默认):输出所有匹配项
- • Include First Match Only:只保留第一个匹配项
四、理解比较逻辑
Compare Datasets节点的比较是两阶段过程:
- 1. 第一阶段:检查你指定的对比字段(如email)在两个输入中是否匹配
- 2. 第二阶段:如果对比字段匹配,再比较这两条记录的所有其他字段,判断数据是完全相同还是有差异
这就是为什么同一条数据可能出现在Same Branch或Different Branch——关键在于除了匹配字段外,其他字段是否也完全相同。
五、实战案例:同步MySQL和企业微信的客户数据
让我们通过一个真实案例来学习如何使用Compare Datasets节点。这个工作流会自动同步MySQL数据库和企业微信的客户数据。
案例场景
你的公司使用MySQL数据库管理客户档案,同时通过企业微信的销售易应用管理客户信息。你需要:
- • 将MySQL中新增的客户自动同步到企业微信
- • 将企业微信中新增的客户自动添加到MySQL
- • 当两边数据不一致时,手动审核或者以最新修改的为准
前置条件
- 1. 企业微信节点:需要安装n8n的企业微信节点,获取企业微信的API凭证(CorpID、Secret等)
- 2. MySQL节点:配置MySQL数据库连接
- 3. 字段对应关系明确,比如MySQL的
customer_id对应企业微信的userid,MySQL的name对应企业微信的name等
工作流构建步骤
步骤1:获取MySQL客户数据
添加MySQL节点,选择"Execute Query"操作,执行SQL查询获取客户数据:
SELECT customer_id, name, email, phone, address, update_time
FROM customers
WHERE update_time > NOW() - INTERVAL 1 DAY;这里我们只查询最近24小时更新的客户,避免一次处理过多数据。
步骤2:获取企业微信客户数据
添加企业微信节点,选择"Read members"操作(或相应的客户获取接口),获取所有客户信息:
配置凭证后,节点会返回企业微信中的所有成员/客户数据。
步骤3:标准化数据格式
在企业微信节点后添加一个Set节点,只保留需要对比的字段,并进行字段名转换,确保两个数据源的字段结构一致:
- • MySQL提供:
customer_id, name, email, phone, address, update_time - • 企业微信提供:
userid, name, email, phone, department, update_timestamp
在Set节点中配置字段映射:
{
"customer_id": $json.userid,
"name": $json.name,
"email": $json.email,
"phone": $json.phone,
"address": "", // 企业微信没有此字段,设置为空
"update_time": $json.update_timestamp
}记得开启Keep Only Set选项,这样只输出我们指定的字段。
步骤4:添加Compare Datasets节点
这是核心步骤:
- • 将MySQL节点连接到Input A
- • 将Set节点(处理后的企业微信数据)连接到Input B
- • Input A Field设置为:
email(MySQL中的邮箱字段) - • Input B Field设置为:
email(企业微信中的邮箱字段) - • 差异处理选择:Use Input A Version(以MySQL为主数据源)
- • 开启Fuzzy Compare,容忍小的格式差异
步骤5:处理"仅在MySQL中"的数据
从In A only Branch输出连接到企业微信节点,操作选择"Create members"或相应的创建操作:
这会将MySQL中独有的客户自动创建到企业微信。配置字段映射,确保MySQL的字段正确对应到企业微信的字段格式。
步骤6:处理"仅在企业微信中"的数据
从In B only Branch输出连接到MySQL节点,操作选择"INSERT":
这会将企业微信中新增的客户自动添加到MySQL数据库。
配置INSERT语句:
INSERT INTO customers (customer_id, name, email, phone, update_time)
VALUES ($json.customer_id, $json.name, $json.email, $json.phone, NOW());步骤7:处理"不同"的数据
这是最复杂但也是最重要的部分——需要判断哪边的数据更新:
- 1. 从Different Branch输出添加IF节点,比较两个数据源的
update_time:
{{ new Date($json.different.input_a.update_time) > new Date($json.different.input_b.update_time) }}- 2. IF节点的"true"分支(MySQL数据更新):连接企业微信Update节点,使用MySQL的数据更新企业微信:
{
"name": $json.different.input_a.name,
"email": $json.different.input_a.email,
"phone": $json.different.input_a.phone
}- 3. IF节点的"false"分支(企业微信数据更新):连接MySQL Update节点,使用企业微信的数据更新MySQL:
UPDATE customers
SET name = '$json.different.input_b.name',
email = '$json.different.input_b.email',
phone = '$json.different.input_b.phone',
update_time = NOW()
WHERE customer_id = '$json.different.input_a.customer_id';步骤8:处理"相同"的数据
从Same Branch输出无需任何操作,因为两边已经一致了。但你可以添加一个webhook或通知节点来记录日志,用于后续审计。
工作流效果
运行这个工作流后,你会看到:
- • ✅ 新增的客户被自动同步到两个系统
- • ✅ 修改过的客户信息以最新版本为准
- • ✅ 完全相同的数据被跳过,避免无意义的更新操作
- • ✅ 所有操作都有记录可查,便于后续审核
六、使用技巧与最佳实践
6.1 选择合适的匹配字段
匹配字段必须是唯一标识符或稳定的业务字段:
- • ✅ 推荐:
email、phone(全局唯一,基本不变) - • ✅ 推荐:
customer_number、userid(系统主键) - • ❌ 避免:
name(可能重复或变更) - • ❌ 避免:
update_time(会频繁变化)
6.2 大数据量优化
如果数据量很大,建议:
- 1. 使用Filter节点先筛选出需要同步的数据(如只同步最近修改的)
- 2. 使用Split In Batches节点分批处理,避免一次加载过多数据
- 3. 在对比前删除不必要的字段,减少内存占用
- 4. 添加Limit节点限制每次处理的数据量(如每次处理100条)
6.3 防止无限循环
在双向同步场景中要特别小心:
问题:如果A系统更新触发工作流同步到B系统,B系统更新又触发工作流同步回A系统,这会导致无限循环!
解决方案:
- 1. 添加标志字段:在MySQL中添加
sync_flag字段,标记由工作流更新的记录 - 2. 过滤同步记录:在触发器中过滤掉由工作流产生的更新
- 3. 设置防抖延迟:工作流完成后等待足够长的时间(如30秒)再检查是否需要再次同步
- 4. 使用单向同步:某些场景下,改为单向同步(只从MySQL→企业微信或只从企业微信→MySQL)会更简单
6.4 启用审计跟踪
为了追踪所有数据变更,可以:
- 1. 将Different Branch的输出(尤其是开启Include Both Versions时)写入日志表
- 2. 发送通知邮件或企业微信消息,告知有数据被同步修改
- 3. 定期生成同步报告,用于审核和合规性检查
七、常见问题排查
问题1:为什么所有数据都出现在"Different Branch"?
原因:数据类型不匹配或格式不一致。比如MySQL的phone是整数13800000000,企业微信是字符串"+86 138-0000-0000"。
解决:
- 1. 开启Fuzzy Compare选项,让节点容忍类型差异
- 2. 在Set节点中统一数据格式,比如都转换为字符串:
{{ String($json.phone) }} - 3. 移除电话号码中的特殊字符:
{{ $json.phone.replace(/\D/g, '') }}
问题2:为什么匹配的数据被判定为"不同"?
原因:除了匹配字段(email)外,其他字段有细微差异。比如MySQL的name是"张三",企业微信是"张三(销售部)",或者有多余空格。
解决:
- 1. 在Options > Fields to Skip Comparing中添加不重要的字段(如
department、remarks) - 2. 在Set节点中统一格式,移除多余空格和特殊字符
- 3. 只对比关键字段,不关心次要字段的差异
问题3:数据量大时工作流执行超时
原因:一次处理的数据太多,MySQL查询或企业微信API调用耗时过长。
解决:
- 1. 在MySQL查询中加入
LIMIT和WHERE条件,只获取需要同步的数据 - 2. 使用Split In Batches节点分批处理(如每批50条)
- 3. 减少不必要的字段,提高数据传输速度
- 4. 考虑在服务器上配置足够的内存和CPU资源
问题4:企业微信API限流
原因:企业微信有调用频率限制,短时间内大量API调用会被限流。
解决:
- 1. 在工作流中添加Wait节点,让API调用之间有延迟(如每10个请求等待1秒)
- 2. 使用批量API接口而不是逐条操作
- 3. 联系企业微信管理员申请提高API调用限额
- 4. 改为每天定时同步一次,而不是实时同步
八、总结
Compare Datasets节点是n8n中最强大的数据处理工具之一。掌握它的关键是理解:
- 1. 四个输出分支的含义和用途
- 2. 匹配字段的选择直接决定对比结果
- 3. 差异处理策略要根据具体业务需求选择
- 4. 善用选项配置可以让对比更灵活、更准确
- 5. 防止无限循环和处理异常情况是实战中最重要的
通过本教程的学习和MySQL与企业微信实战案例,相信你已经能够运用Compare Datasets节点解决实际的数据对比和同步问题了。记住,多尝试、多实践,你会发现更多有趣的应用场景!
引用链接
[1] 官方文档: https://docs.n8n.io/integrations/builtin/core-nodes/n8n-nodes-base.comparedatasets/
[2] n8n系列教程: https://www.undsky.com/blog/?category=n8n%E6%95%99%E7%A8%8B#