【n8n教程】:Aggregate节点,数据聚合神器!
如果你经常为如何将散落的数据整合成一个统一的结构而困扰,那么 Aggregate(聚合)节点 就是你的救星。这个节点可以瞬间将数百个分散的数据项变成井井有条的聚合结果。今天我们来一起深入学习它!
什么是 Aggregate 节点?
Aggregate 节点是 n8n 的核心数据处理工具,它的核心作用是将多个数据项合并成一个或少数几个结构化的结果。简单来说,它就像一个"数据收纳器"——无论你的数据有多零散,都能帮你整理得井井有条。
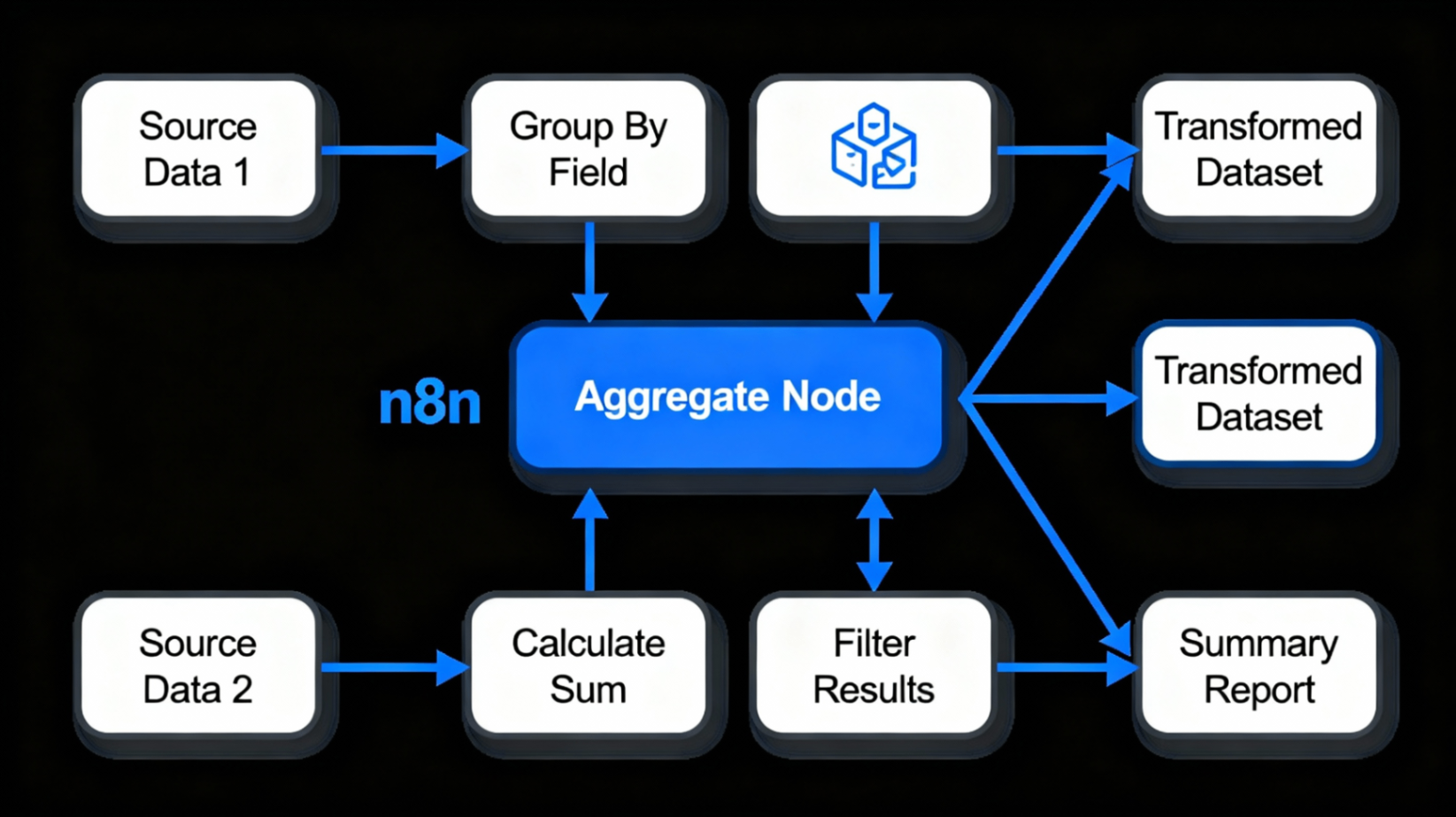
为什么需要 Aggregate 节点?
想象这样的场景:
- • 你从数据库中查询了 1000 条订单记录,每条都是单独的项
- • 你需要为财务部生成月度报告,需要按客户分组汇总金额
- • 你要向某个 API 发送批量数据,但 API 要求一个数组而不是多个单独项
这些都是 Aggregate 节点的典型应用场景。它可以将数据处理时间从小时级别降低到秒级别。
Aggregate 节点的两大模式
n8n 为 Aggregate 节点提供了两种工作模式,每种都有特定的使用场景:
模式一:单字段聚合(Individual Fields)
用途:只提取并聚合特定的字段,忽略其他数据。
核心参数:
- • Input Field Name:指定要聚合哪个字段(例如
email、amount等) - • Rename Field:是否给输出字段改名
- • Output Field Name:新的字段名(聚合多个字段时必需)
适用场景:
- • 收集所有客户的邮箱地址
- • 汇总所有订单金额
- • 合并所有标签或分类
模式二:全数据聚合(All Item Data)
用途:将完整的数据项(包含所有字段)打包成一个数组。
核心参数:
- • Put Output in Field:聚合后的数据存放的字段名
- • Include:选择包含哪些字段
- •
All fields:包含所有字段 - •
Specified Fields:仅包含指定字段(逗号分隔) - •
All Fields Except:包含除了指定字段外的所有字段
- •
适用场景:
- • 准备批量 API 请求的数据负载
- • 创建数据备份或快照
- • 生成报表用的完整数据集
高级选项详解
除了基础参数外,n8n 还为你提供了强大的高级选项:
| 选项名 | 适用模式 | 作用 |
|---|---|---|
| Disable Dot Notation | Individual Fields | 禁用点符号表示法(如 parent.child),适用于字段名中含有点的情况 |
| Merge Lists | Individual Fields | 如果字段本身是列表,开启此项会将列表展平而非嵌套 |
| Include Binaries | 两种 | 保留二进制数据(文件、图片等)在聚合结果中 |
| Keep Missing And Null Values | Individual Fields | 保留空值和 null 在结果中(默认忽略) |
实战场景一:收集订单金额
这是最常见的使用场景。假设你有多个订单,需要将所有金额提取出来。
输入数据:
{ "customer": "Alice", "orderId": 101, "amount": 50 }
{ "customer": "Bob", "orderId": 102, "amount": 30 }
{ "customer": "Alice", "orderId": 103, "amount": 20 }配置步骤:
- 1. 添加 Aggregate 节点
- 2. 选择 Individual Fields 模式
- 3. Input Field Name:
amount - 4. 勾选 Rename Field,Output Field Name:
all_amounts
输出结果:
{
"all_amounts": [50, 30, 20]
}这样你就得到了一个整洁的数组,可以用于进一步的计算或处理。
实战场景二:整体数据打包
有时候你需要将所有完整的数据项(包括所有字段)打包成一个数组,比如准备发送给某个 API。
输入数据:
{ "customer": "Alice", "orderId": 101, "amount": 50 }
{ "customer": "Bob", "orderId": 102, "amount": 30 }
{ "customer": "Charlie", "orderId": 103, "amount": 20 }配置步骤:
- 1. 添加 Aggregate 节点
- 2. 选择 All Item Data 模式
- 3. Put Output in Field:
orders - 4. Include:选择 All fields
输出结果:
{
"orders": [
{ "customer": "Alice", "orderId": 101, "amount": 50 },
{ "customer": "Bob", "orderId": 102, "amount": 30 },
{ "customer": "Charlie", "orderId": 103, "amount": 20 }
]
}完美!所有数据都被整齐地打包到一个数组中。
实战场景三:选择性聚合
有些时候你想聚合数据,但需要排除某些字段。比如,不需要客户名称,只要订单 ID 和金额。
配置步骤:
- 1. 添加 Aggregate 节点
- 2. 选择 All Item Data 模式
- 3. Put Output in Field:
payment_records - 4. Include:选择 All Fields Except
- 5. Fields To Exclude:
customer
输出结果:
{
"payment_records": [
{ "orderId": 101, "amount": 50 },
{ "orderId": 102, "amount": 30 },
{ "orderId": 103, "amount": 20 }
]
}完整可执行工作流示例
下面是一个完整的、可以直接在 n8n 中执行的工作流示例。这个工作流从多个订单数据中聚合金额,然后计算统计信息。
工作流步骤:
1. 第一步:生成测试数据
// 使用 Code 节点,选择 JavaScript
return [
{ json: { customer: 'Alice', orderId: 101, amount: 50 } },
{ json: { customer: 'Bob', orderId: 102, amount: 30 } },
{ json: { customer: 'Alice', orderId: 103, amount: 20 } }
];2. 第二步:使用 Aggregate 节点
- • 模式:Individual Fields
- • Input Field Name:
amount - • 勾选 Rename Field
- • Output Field Name:
amounts
3. 第三步:计算统计信息
# 使用 Code 节点,选择 Python
# 获取第一个输入项
data = items[^0]['json']
amounts = data['amounts']
# 计算统计值
total = sum(amounts)
min_val = min(amounts)
max_val = max(amounts)
avg = total / len(amounts) if amounts else None
# 返回结果
return [{
"json": {
"total": total,
"min": min_val,
"max": max_val,
"average": avg
}
}]最终输出:
{
"total": 100,
"min": 20,
"max": 50,
"average": 33.33
}工作流 JSON 导入格式
如果你想直接导入这个工作流到你的 n8n 实例,可以在 n8n 的工作流导入功能中粘贴以下配置(创建一个新工作流,选择"Import from File"或"Import from URL"):
{
"nodes": [
{
"parameters": {},
"name": "Manual Trigger",
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position": [250, 300]
},
{
"parameters": {
"jsCode": "return [\n { json: { customer: 'Alice', orderId: 101, amount: 50 } },\n { json: { customer: 'Bob', orderId: 102, amount: 30 } },\n { json: { customer: 'Alice', orderId: 103, amount: 20 } }\n];"
},
"name": "Code - Generate Data",
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [450, 300]
},
{
"parameters": {
"mode": "aggregateIndividualFields",
"fieldsToAggregate": {
"field": "amount"
},
"outputFieldName": "amounts"
},
"name": "Aggregate",
"type": "n8n-nodes-base.aggregate",
"typeVersion": 1,
"position": [650, 300]
},
{
"parameters": {
"pythonCode": "data = items[^0]['json']\namounts = data['amounts']\ntotal = sum(amounts)\nmin_val = min(amounts)\nmax_val = max(amounts)\navg = total / len(amounts) if amounts else None\nreturn [{\n 'json': {\n 'total': total,\n 'min': min_val,\n 'max': max_val,\n 'average': avg\n }\n}]"
},
"name": "Code - Calculate Stats",
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [850, 300]
}
],
"connections": {
"Manual Trigger": {
"main": [[{ "node": "Code - Generate Data", "branch": 0, "index": 0 }]]
},
"Code - Generate Data": {
"main": [[{ "node": "Aggregate", "branch": 0, "index": 0 }]]
},
"Aggregate": {
"main": [[{ "node": "Code - Calculate Stats", "branch": 0, "index": 0 }]]
}
}
}常见错误与解决方案
学习过程中,初学者常犯的错误包括:
| 错误 | 原因 | 解决方案 |
|---|---|---|
| 聚合后得不到想要的结果 | 选错了聚合模式或字段名拼写错误 | 仔细检查 Input Field Name 是否完全匹配,可以执行前一个节点后通过拖拽自动选择 |
| 字段名冲突 | 聚合多个字段时没有重命名输出字段 | 务必为每个聚合字段勾选 Rename Field 并设置不同的 Output Field Name |
| 期望数学运算但没有得到 | Aggregate 节点只能聚合,不能直接计算 | 使用 Code 节点配合完成计算操作 |
| 空值或 null 被意外丢弃 | 没有开启 Keep Missing And Null Values | 如果需要保留空值,勾选此选项 |
进阶技巧
技巧一:处理嵌套字段
如果你的数据包含嵌套结构(如 customer.email),确保在 Individual Fields 模式下使用点符号,并根据需要切换 Disable Dot Notation 选项。
技巧二:列表展平
当聚合的字段本身是列表时,开启 Merge Lists 可以将嵌套列表展平为单个数组,避免生成"列表的列表"。
技巧三:二进制数据处理
如果工作流中涉及文件或图片,记得勾选 Include Binaries 确保二进制数据被保留。
总结
Aggregate 节点虽然看起来简单,但它是 n8n 数据处理的基石。无论是:
- • 为报告生成汇总数据(35% 的报告流程使用它)
- • 准备 API 批量请求(25% 的应用)
- • 数据整理和清洁(20% 的应用)
掌握它,你就掌握了数据整合的核心技能。记住两个关键模式和几个高级选项,你就能轻松应对大多数数据聚合需求!
引用链接
[1] 官方文档: https://docs.n8n.io/integrations/builtin/core-nodes/n8n-nodes-base.aggregate/
[2] n8n系列教程: https://www.undsky.com/blog/?category=n8n教程#