【Dify】:使用 RAGFlow + Firecrawl 增强知识库
为什么要这样做?
Dify 的定位
Dify 擅长的:
- • 🎨 工作流编排:像搭积木一样组装 AI 流程
- • 🤖 模型管理:统一管理各种 AI 模型(GPT、Claude、国产大模型等)
- • 🔌 API 集成:快速对接各种外部服务
Dify 的局限:
- • 📚 知识库功能相对简单:内置的知识库更偏向通用型,对文档的解析和检索能力有限
最佳组合方案
把专业的事交给专业的工具:
- • 🧠 RAGFlow:专业的知识库管理工具,文档解析更深入、检索更精准
- • 🕷️ Firecrawl:专业的网页爬虫工具,智能提取网页内容
- • 🎯 Dify:作为总控制台,编排整个 AI 工作流
打个比方:
- • Dify = 项目经理(负责协调和管理)
- • RAGFlow = 图书馆管理员(专业管理文档知识)
- • Firecrawl = 信息收集员(专业收集网页内容)
准备工作
前提条件:
- 1. ✅ 已经安装并运行了 Dify
- 2. ✅ 已经安装并运行了 RAGFlow
- 3. ✅ (可选)已经安装并运行了 Firecrawl
如果还没安装,请先查看:
第一部分:对接 RAGFlow
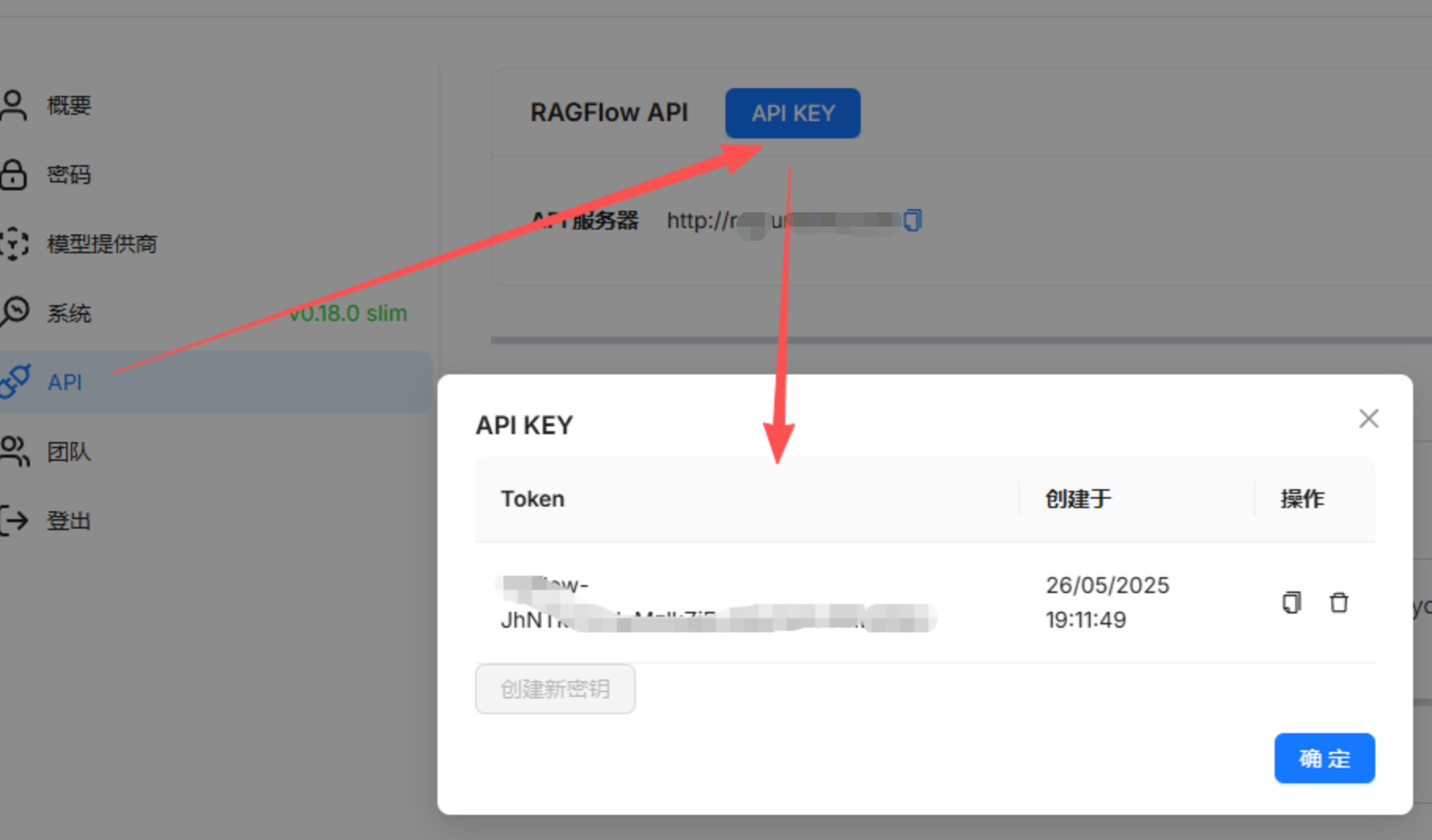
第一步:获取 RAGFlow 的 API Key
作用: API Key 就像是一把"钥匙",让 Dify 能访问 RAGFlow 的知识库。
操作步骤:
- 1. 打开 RAGFlow 后台
- 2. 进入设置或个人中心页面
- 3. 找到并复制 API Key(保存好,后面要用)
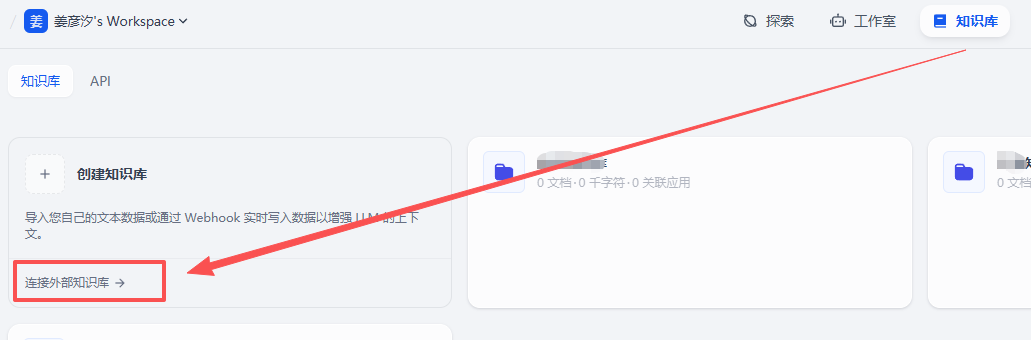
第二步:在 Dify 中连接外部知识库
操作步骤:
- 1. 打开 Dify 后台
- 2. 进入"知识库"页面
- 3. 点击"连接外部知识库"或类似按钮
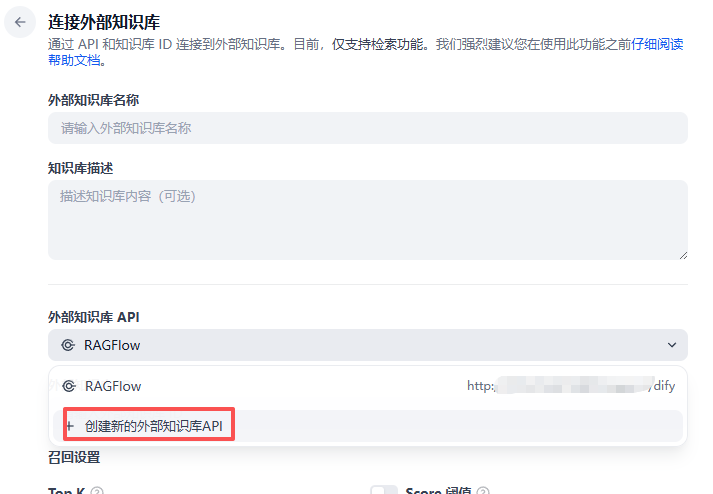
第三步:创建外部知识库 API 连接
操作步骤:
- 1. 点击"创建新的外部知识库 API"
- 2. 填写配置信息(见下方说明)
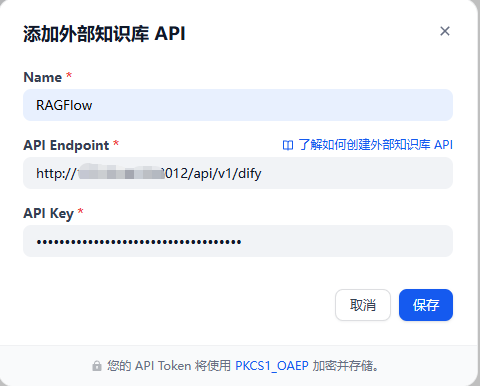
配置说明:
API Endpoint(API 地址):
http://RAGFlow服务器地址/api/v1/dify重要提示:
- • 如果 Dify 和 RAGFlow 在同一台服务器,使用内网 IP(如
http://127.0.0.1:端口号/api/v1/dify) - • 如果在不同服务器,使用 RAGFlow 的实际访问地址
API Key(API 密钥):
填写第一步获取的 API Key
配置示例:
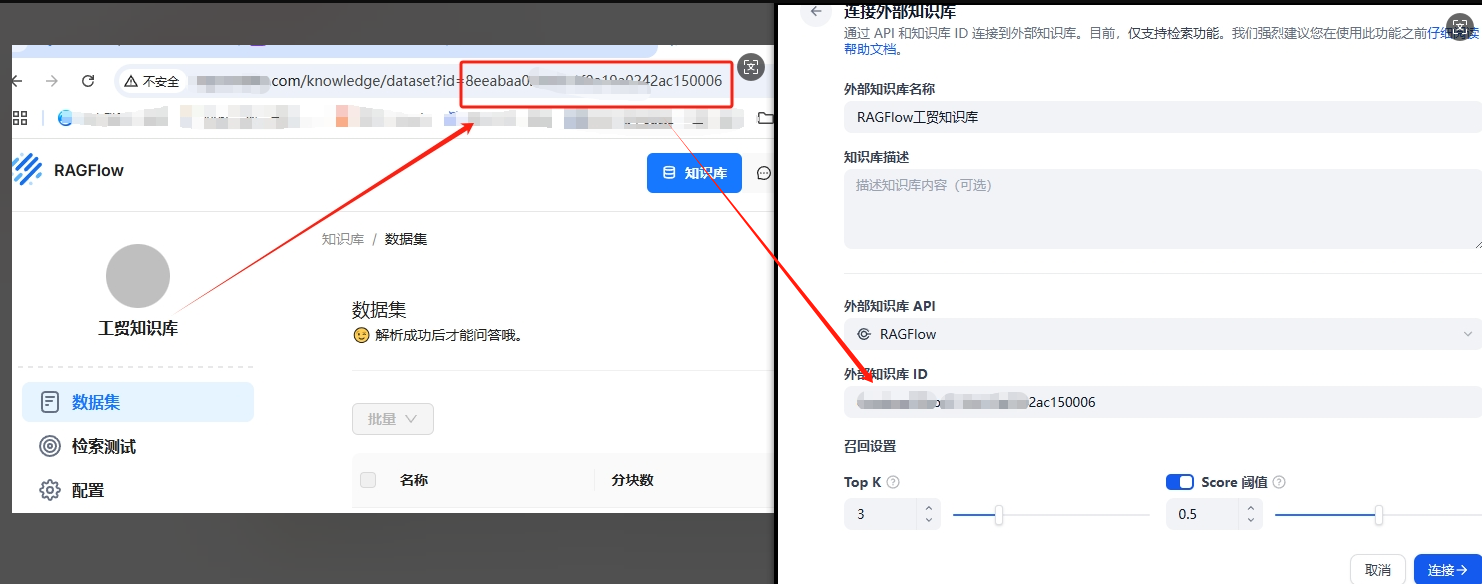
第四步:设置外部知识库 ID
作用: 指定要使用 RAGFlow 中的哪个知识库。
操作步骤:
- 1. 在 RAGFlow 中找到你的知识库 ID
- 2. 在 Dify 中填写这个 ID
进阶技巧:下载 RAGFlow 知识库中的文件
使用场景: 如果你需要从 RAGFlow 中下载原始文件(比如备份或查看原文件)。
官方文档: https://ragflow.io/docs/dev/http_api_reference#download-document
下载文件的步骤
步骤 1:理解 API 地址格式
/api/v1/datasets/{dataset_id}/documents/{document_id}参数说明:
- •
dataset_id:知识库 ID(在上面第四步的截图中可以找到) - •
document_id:文档的真实 ID(需要通过查询获取)
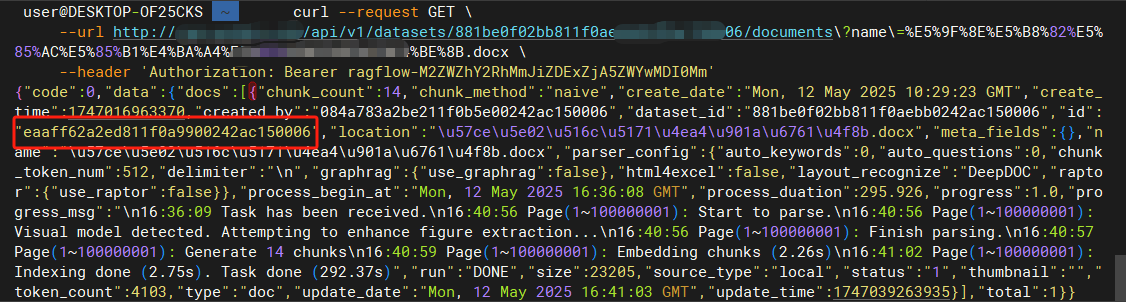
步骤 2:获取文档的真实 ID
问题: 当你检索知识库时,返回的 document_id 其实是文档名称,不是真实的 ID。
检索返回的数据示例:
{
"metadata": {
"_source": "knowledge",
"dataset_id": "80cb63be-20e1-4123-acb0-27331820c8",
"dataset_name": "我的知识库",
"document_id": "产品说明.docx", // 这是文档名称,不是真实ID
"document_name": "产品说明.docx",
"data_source_type": "external",
"retriever_from": "workflow",
"score": 0.2406198464565076,
"position": 8
},
"title": "产品说明.docx",
"content": "文档内容..."
}解决方法: 根据文档名称查询真实的文档 ID
curl --request GET \
--url http://RAGFlow地址/api/v1/datasets/88be0f02bb811faebb0242ac50006/documents?name=产品说明.docx \
--header 'Authorization: Bearer ragflow-你的API密钥'查询结果示例:
步骤 3:使用真实 ID 下载文件
下载命令:
curl --request GET \
--url http://RAGFlow地址/api/v1/datasets/知识库ID/documents/文档真实ID \
--header 'Authorization: Bearer ragflow-你的API密钥' \
--output ./产品说明.docx完整示例:
curl --request GET \
--url http://127.0.0.1:8012/api/v1/datasets/881be0f0bb811f0aebb02ac150006/documents/eaaff2a2ed811f0a900242ac15006 \
--header 'Authorization: Bearer ragflow-M2ZWZhYRhMmJiZDEZjA5ZWYwMDI0Mm' \
--output ./产品说明.docx下载成功示例:

小提示:
- • 记得替换命令中的地址、ID 和 API 密钥
- • 文件会下载到当前目录
第二部分:对接 Firecrawl
什么是 Firecrawl?
Firecrawl 是一个智能网页爬虫工具,可以把网页内容转换成干净的 Markdown 格式,非常适合作为 AI 知识库的数据源。
使用场景:
- • 📰 定期抓取行业新闻、技术博客
- • 📖 批量抓取在线文档、教程
- • 🔍 监控竞品网站信息
官方文档: https://docs.firecrawl.dev/zh/introduction
第一步:在 Dify 中配置 Firecrawl
操作步骤:
- 1. 打开 Dify 后台
- 2. 进入"设置" → "数据来源"
- 3. 找到 Firecrawl 配置项
- 4. 填写 Firecrawl 的 API 地址和密钥
配置示例:
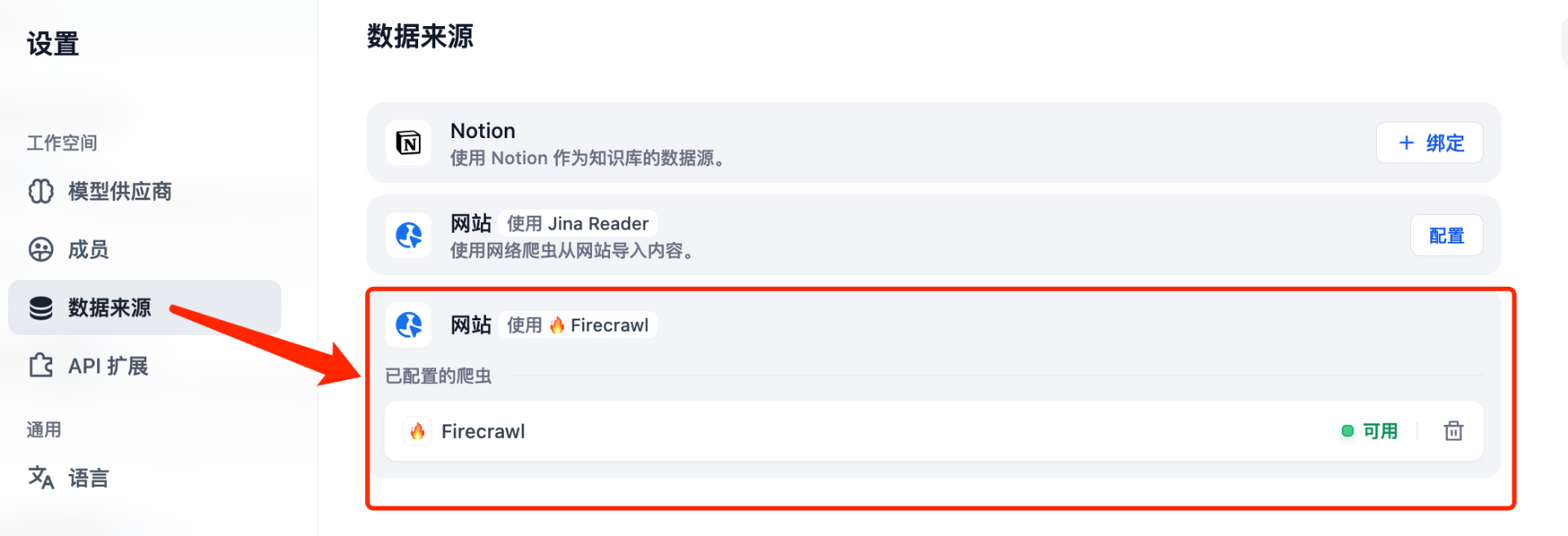
配置说明:
- • API 地址:如果是本地部署,填写
http://127.0.0.1:3002(或你设置的端口) - • API Key:如果关闭了授权验证,可以留空;否则填写你的密钥
第二步:创建使用 Firecrawl 的知识库
操作步骤:
- 1. 在 Dify 中创建新知识库
- 2. 选择"从网页导入"或"Firecrawl"数据源
- 3. 输入要爬取的网页地址
- 4. 等待 Firecrawl 自动抓取和处理
示例:
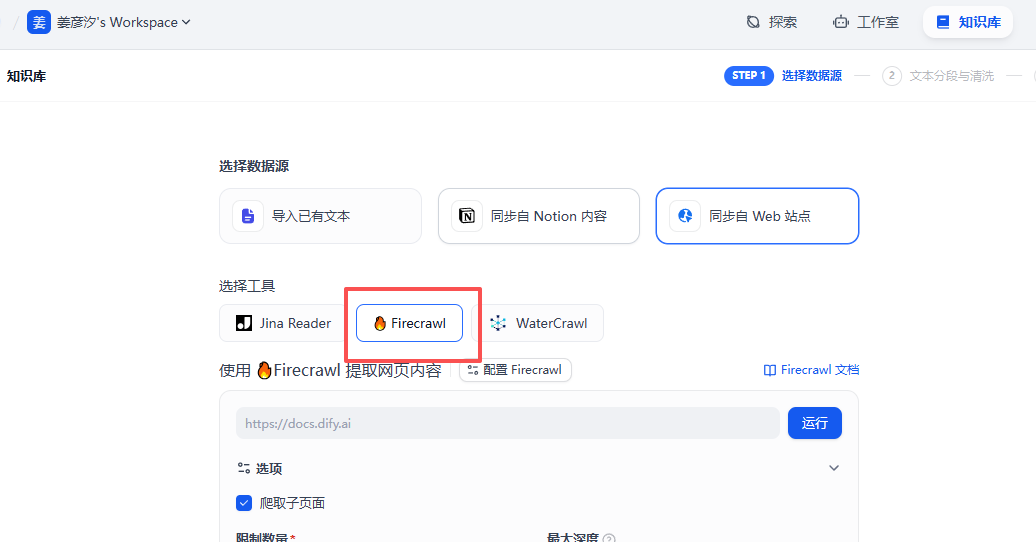
使用建议:
- • ✅ 适合爬取文档类网站(如官方文档、教程)
- • ✅ 内容会自动转换成 Markdown,方便 AI 理解
- • ❌ 不要频繁爬取同一网站,避免给对方服务器压力
- • ❌ 遵守网站的 robots.txt 规则
总结
通过这篇教程,你已经学会了:
核心收获
- 1. ✅ 理解三者的定位
- • Dify:工作流编排和模型管理
- • RAGFlow:专业知识库管理
- • Firecrawl:智能网页爬虫
- 2. ✅ 对接 RAGFlow
- • 获取并配置 API Key
- • 在 Dify 中连接外部知识库
- • 设置知识库 ID
- 3. ✅ 对接 Firecrawl
- • 配置 Firecrawl API
- • 使用 Firecrawl 创建知识库
- 4. ✅ 进阶技巧
- • 下载 RAGFlow 中的原始文件
工作流程
网页内容 → Firecrawl(爬取清洗) → RAGFlow(深度解析存储) → Dify(智能检索和对话)下一步建议
- 1. 测试知识库
- • 在 RAGFlow 中上传一些测试文档
- • 在 Dify 中创建一个简单的对话应用
- • 测试知识库检索效果
- 2. 优化配置
- • 根据文档类型调整 RAGFlow 的解析策略
- • 设置合适的检索参数(相似度阈值、返回数量等)
- 3. 扩展应用
- • 尝试构建客服机器人
- • 创建文档问答助手
- • 制作内部知识库查询工具
常见问题
Q1: Dify 连接 RAGFlow 时报错怎么办?
- • 检查 API 地址是否正确
- • 确认 API Key 是否有效
- • 查看防火墙是否阻止了连接
Q2: Firecrawl 爬取失败怎么办?
- • 检查网站是否允许爬取(查看 robots.txt)
- • 确认 Firecrawl 服务是否正常运行
- • 尝试使用其他网站测试
Q3: 为什么不直接用 Dify 的内置知识库?
- • Dify 内置知识库适合简单场景
- • RAGFlow 对复杂文档的解析更深入
- • 根据实际需求选择合适的方案
祝你使用愉快!🎉
引用链接
[1] Dify 安装教程: AITool-Dify.md
[2] RAGFlow 安装教程: AITool-RAGFlow.md
[3] Firecrawl 安装教程: AITool-Firecrawl.md